
Do you have some scraping code that works for some sites but not others, even though you're sure your method to get data out of the site is working well?
Or maybe, when you make your requests, the page content is very different from what you see in your browser?
The problem is most likely JavaScript. Or, should I say, lack of JavaScript.
In my courses I teach you how to build web scraping systems very quickly and easily by using two popular Python libraries: requests and beautifulsoup4. However, sometimes the scraping doesn't quite work.
When you load up a website you want to scrape using your browser, the browser will make a request to the page's server to retrieve the page content. That's usually some HTML code, some CSS, and some JavaScript.
When we are doing web scraping, all we're interested in is the HTML. That's because the HTML usually contains all the information in the page. CSS is used to perform styling, and our scraping programs don't care what the page looks like.
So we load the HTML using the requests mode, and parse it using BeautifulSoup... and voilà! We have the information we need and we can feed it to our programs.
A key difference between loading the page using your browser and getting the page contents using requests is that your browser executes any JavaScript code that the page comes with. Sometimes you will see the initial page content (before the JavaScript runs) for a few moments, and then the JavaScript kicks in.
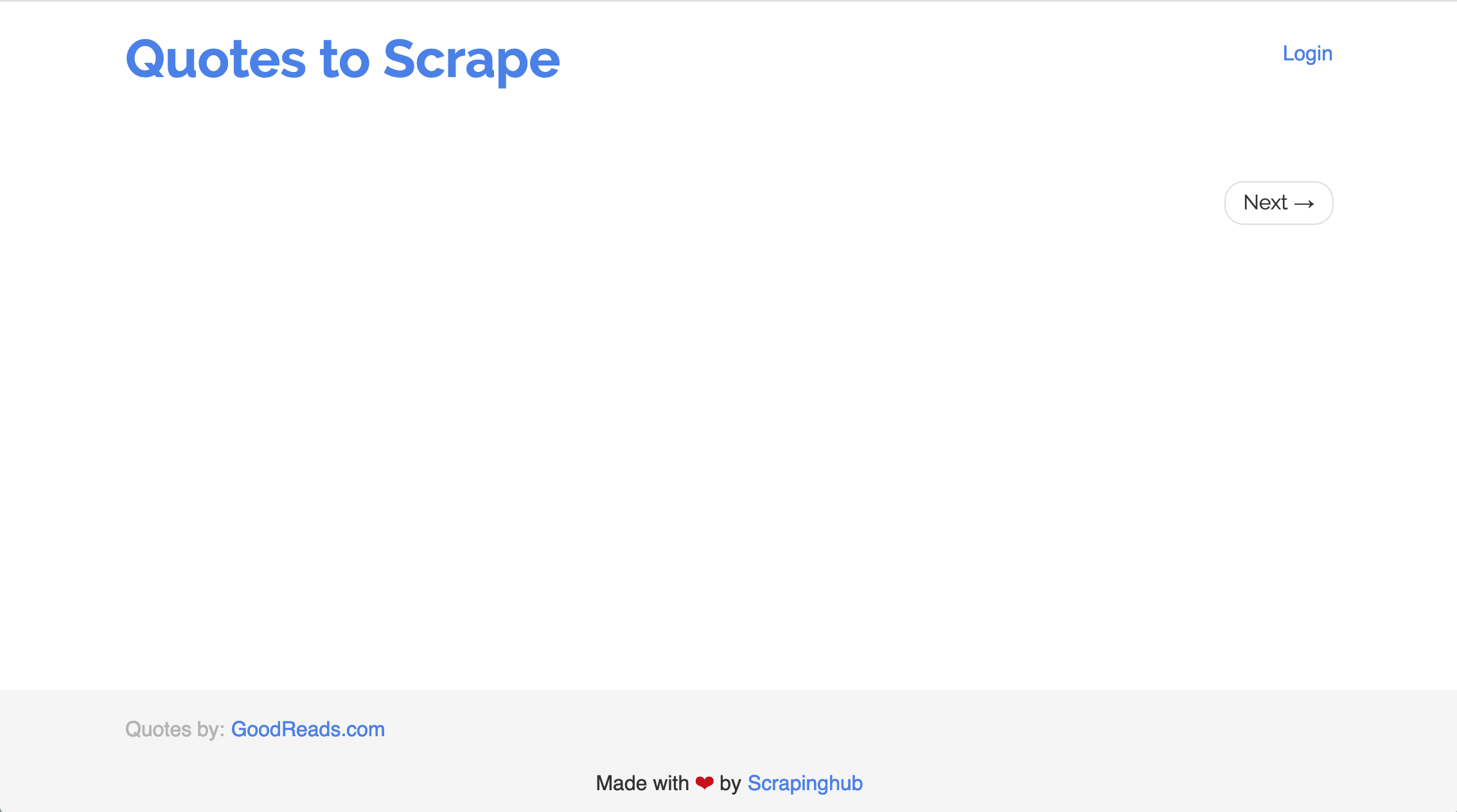
Here's an example page right before JavaScript kicks in:
And here it is a few milliseconds after, once JavaScript has kicked in:
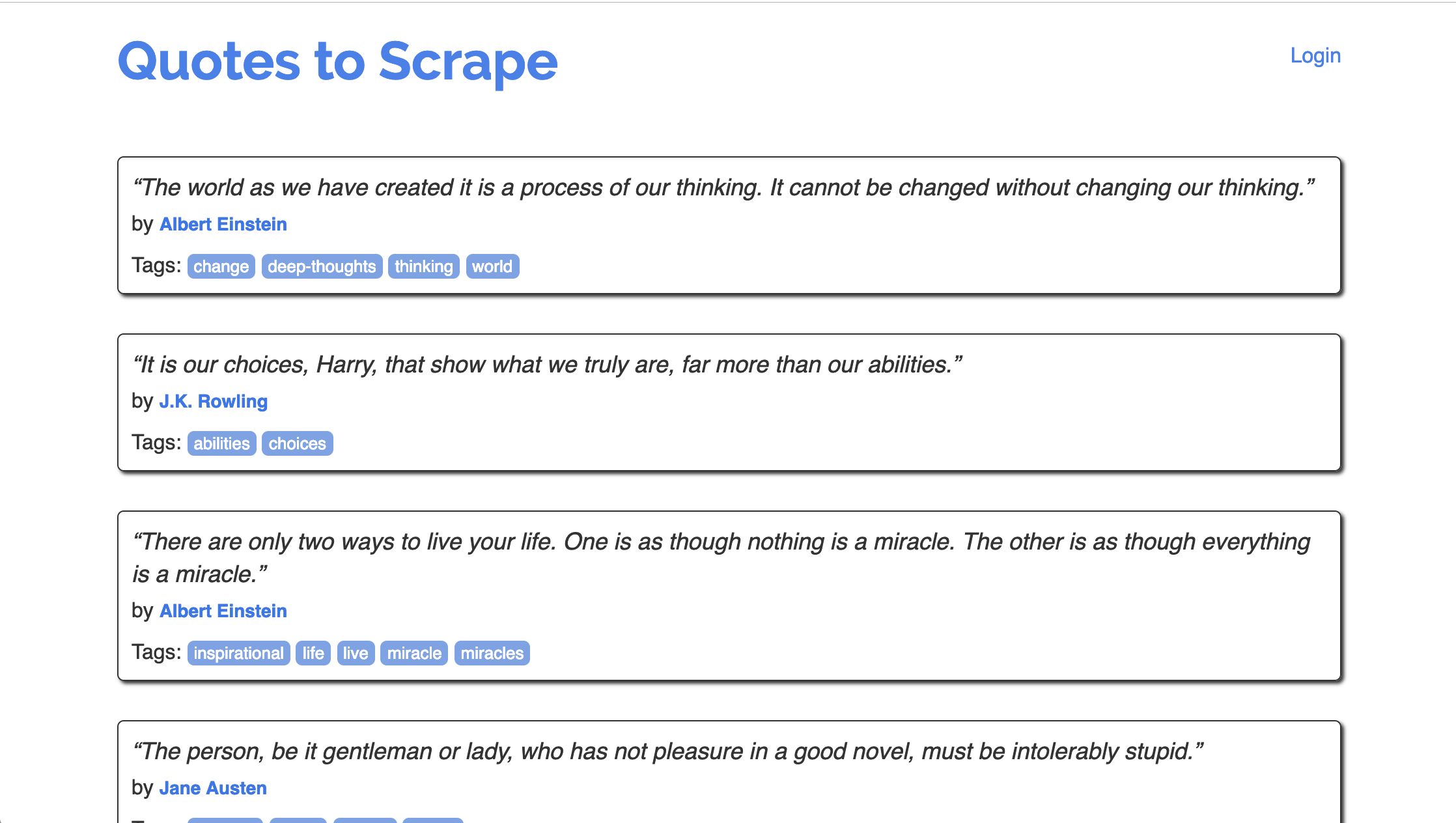
As you can see, the initial page (before JavaScript runs), has no data of interest to us. After JavaScript runs, it has the data we want.
When we make a request for page content using requests, the JavaScript does not run. Therefore, you would only see the initial page.
It's a very frequent problem in my courses to see this happen. Unfortunately, the only way to get the page after JavaScript has ran is, well, running the JavaScript. You need a JavaScript engine in order to do that. That means you need a browser or browser-like program in order to get the final page.
Using requests and BeautifulSoup you cannot achieve this, but there are other libraries that can help.
- Selenium is a browser automation tool, which means you can use Selenium to control a browser. You can make Selenium load the page you're interested in, evaluate the JavaScript, and then get the page content.
- requests-html is another library that will let you evaluate the JavaScript after you've retrieved the page. It uses
requeststo get the page content, and then runs the page through the Chrome browser engine (Chromium) in order to "calculate" the final page. However, it's still very much under active development and I've had a few problems with it.
Another problem with scraping
In a few cases—although less often—there can be another problem: not getting to the initial page content at all!
This can happen because many sites want to prevent us from scraping them. After all, think about it: our robot is not going to purchase anything, and also our robot will not look at or be affected by advertisements. However, our robot will load the page which means the site has to spend money paying for servers which serve the page to our robot.
It really is a lose-lose for them in many cases, so they block us.
Most sites have a file called robots.txt which tells us which parts of the site we are allowed to scrape, and which parts we are not allowed to scrape. Note that not being allowed does not mean we will get blocked, just that you shouldn't do it.
For example, here's Amazon's robots.txt: https://www.amazon.co.uk/robots.txt
You can see many parts of Amazon are Disallowed, which means you should not scrape them. Amazon may block your robot if it is sure it is a robot.
There are ways to try to circumvent blocks, but it's a nasty thing to do!
Alternatives to scraping
Instead of scraping, many websites offer APIs that you can use to access their data. For example, Twitter is a big one where you should use their API instead of scraping them.
There's a couple reasons for a website to offer an API instead of allowing scraping. The first one is they have more control over access, and therefore can have multiple access plans where they charge you money. The second is that they have more control of who can access data (for example, Twitter requires that you apply for API access). The third is that it's often cheaper in terms of server and bandwidth costs to give you the raw data through an API than to give you the full page and let you find the information you need.
In addition, APIs are usually easier for you to use, rather than scraping. Before starting a scraping project, check that the site you're interested in doesn't have a public API!